
Huawei PanGu-Σ (PanGu Sigma) — крупномасштабная языковая модель со спарс-архитектурой, созданная для эффективного обучения и последующего развертывания под конкретные домены и задачи. Основа подхода — сочетание плотных (shared) слоёв Transformer и разреженных слоёв экспертов, чтобы масштабировать параметры без пропорционального роста вычислений. Полный первоисточник — технический отчёт PanGu-Σ на arXiv.
Главная идея PanGu-Σ — дать бизнесу и исследователям гибкость: обучить «гиганта», но в продакшн доставлять извлекаемый доменный субмодуль (sub-model), который легче обслуживать и быстрее масштабировать под прикладные сценарии.
📌 Что такое PanGu-Σ и чем она отличается от «обычных» LLM?
PanGu-Σ проектировалась вокруг практичной дилеммы: как обучать триллион параметров на ограниченном кластере и при этом не «убить» скорость обучения и стоимость развертывания. Для этого в архитектуре заложены два ключевых механизма:
- 🧠 Random Routed Experts (RRE) — разреженные «эксперты» в верхних слоях, куда токены направляются по домену и затем распределяются случайно внутри группы.
- ⚙️ Expert Computation and Storage Separation (ECSS) — разнесение вычислений и хранения для экспертов, чтобы снизить обмен данными и ускорить обучение.
Мысль экспертов: разреженные эксперты дают «масштаб параметров», но выигрыш появляется только тогда, когда маршрутизация и система обучения не упираются в коммуникации и дисбаланс нагрузки.
Риторический вопрос: зачем строить триллион параметров, если потом всё равно не хочется обслуживать триллион в продакшне? Именно здесь PanGu-Σ делает ставку на «обучили один раз — развернули фрагмент, который нужен домену».
🧩 Архитектура PanGu-Σ: как устроена модель
Архитектура — это «смешанный стек»: нижние слои Transformer остаются плотными и общими (shared knowledge), а верхние слои получают разреженную активацию экспертов для доменной специализации. Важная деталь — у разных доменов могут быть разные embedding-слоты/матрицы, чтобы аккуратнее разводить специализации.
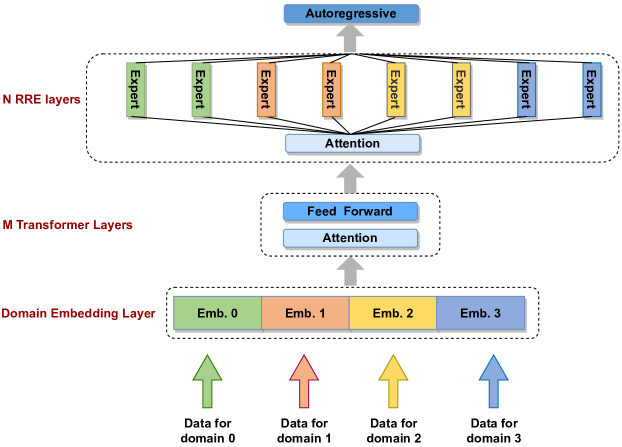
Схема: смешанная архитектура PanGu-Σ — shared Transformer-слои + sparse RRE-слои для доменов.
Random Routed Experts (RRE): «эксперты без обучаемого гейта»
В классических MoE-подходах часто есть обучаемый роутер (gating), который решает, к каким экспертам отправить токены. В PanGu-Σ используется другой принцип: сначала токен попадает в группу экспертов по домену/задаче, затем внутри группы выбирается эксперт случайно и равномерно. Это снижает риски дисбаланса и уменьшает издержки на роутинг.
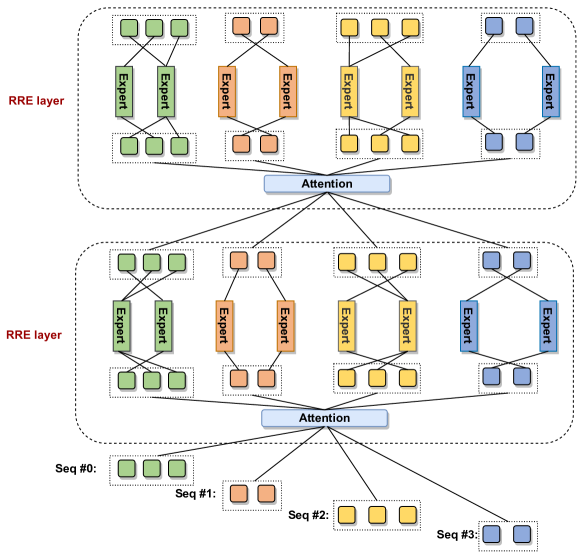
Схема RRE: домен → группа экспертов → выбор эксперта без обучаемого gating-модуля.
ECSS: ускорение обучения за счёт разделения вычислений и хранения
Одна из болевых точек обучения гигантских моделей — коммуникации и оптимизатор (состояния, градиенты, обновления). ECSS использует разреженность: в каждой итерации активируется лишь часть экспертов, поэтому можно сократить пересылки и операции обновления для неактивных компонентов.
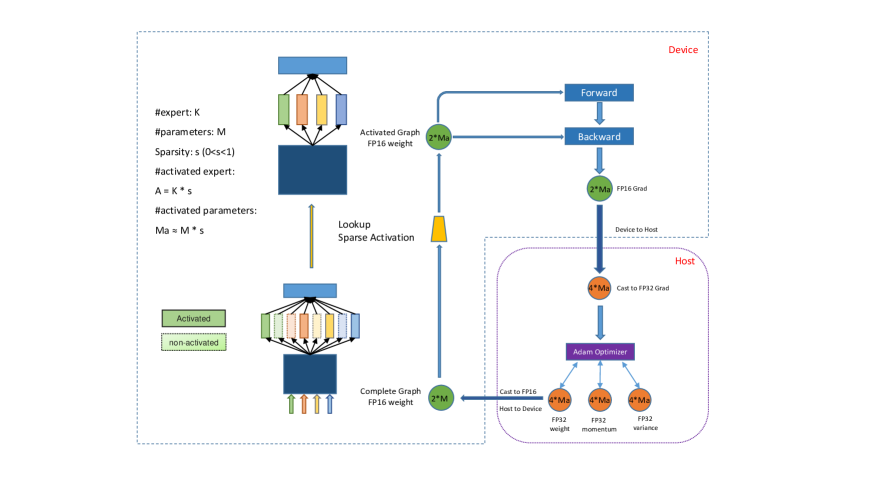
ECSS: активируются только нужные эксперты — меньше обмена данными и выше итоговая пропускная способность.
Практическая интерпретация: ECSS — это способ «не трогать всё» на каждой итерации, а обновлять только то, что реально участвовало в вычислении.
📈 Производительность и масштабирование: что заявлено в отчёте
В техническом отчёте модель описана как триллионная по масштабу, обученная на кластере ускорителей Ascend и фреймворке MindSpore. Также приводятся метрики пропускной способности и ускорения при включении ECSS.
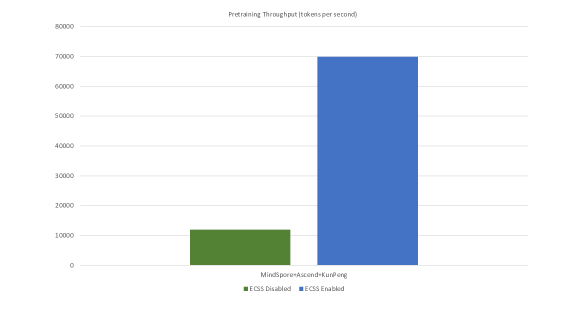
График: увеличение throughput (token/s) при включении ECSS в обучении PanGu-Σ.
Таблица: какие решения закрывают какие задачи
| Задача/ограничение | Типичная проблема | Что делает PanGu-Σ | Практический результат |
|---|---|---|---|
| Масштаб параметров | Дорого обучать плотный Transformer | Разреженные эксперты (RRE) в верхних слоях | Больше параметров при контролируемых вычислениях |
| Стабильность роутинга | Дисбаланс нагрузки у learnable gating | Двухуровневая маршрутизация без обучаемого гейта | Предсказуемая нагрузка и проще эксплуатация |
| Коммуникации и оптимизатор | Узкое место — обмен данными и обновления | ECSS: хранение/вычисление экспертов разнесены, активируется часть | Выше throughput и лучше масштабирование на кластере |
| Развертывание | Нельзя/невыгодно обслуживать 1T в продакшне | Извлечение доменного субмодуля (sub-model) | Снижение стоимости инференса и ускорение вывода в прод |
🛠️ Как взаимодействовать с PanGu-Σ на практике: рабочая инструкция
Важно: PanGu-Σ — это прежде всего архитектура + системные техники обучения. Взаимодействие в реальных проектах обычно строится через два сценария: (1) использование доступного доменного API/сервиса, (2) интеграция/дообучение извлечённого субмодуля под задачу.
✅ Пошаговый чек-лист (сохраните этот список себе)
- Определить домен: диалог, QA, перевод, код, корпоративные документы, отраслевые знания и т.д.
- Выбрать стратегию: “использовать как сервис” или “извлечь субмодель + донастроить”.
- Подготовить данные: очистка, дедупликация, разметка домена, форматирование под выбранный pipeline.
- Настроить промпт-шаблоны: системные инструкции, контекст, требования к стилю и форматам ответов.
- Запустить тестовый прогон: 50–200 запросов, собрать ошибки (галлюцинации, тон, формат, факты).
- Усилить контроль качества: правила, фильтры, retrieval (RAG), ограничение тем, пост-валидация.
- Вынести в прод: мониторинг, метрики качества, регрессии, периодическое обновление данных.
🎯 Проблема — Решение — Результат (как обычно выглядит внедрение)
Проблема: корпоративной команде нужен ассистент для техподдержки, но общий LLM даёт “слишком общие” ответы и путает специфику домена.
Решение: специалисты выделяют домен (FAQ, тикеты, документация), вводят доменную идентификацию, подключают retrieval по базе знаний и настраивают шаблоны промптов под форматы ответов.
Результат: повышается точность и единообразие ответов, снижается нагрузка на линию поддержки, а стоимость обслуживания уменьшается за счёт более «узкой» модели/контура вывода.
Подсказка внедрения: если ответы должны быть строго “по базе”, лучше не надеяться на “знание модели”, а закрепить факты через RAG и валидацию.
Шаблоны промптов для прикладных задач
1) Поддержка/FAQ
- 📌 Роль: «Ты ассистент службы поддержки компании. Отвечай кратко и по регламенту».
- 📌 Ограничения: «Если данных недостаточно — задай уточняющий вопрос. Не выдумывай».
- 📌 Формат: «Ответ: … / Шаги: 1…2… / Если не помогло: …».
2) Аналитика документов
- 📄 «Суммируй документ в 7–10 пунктах, выдели риски, сроки, ответственных».
- 🔍 «Составь список противоречий и мест, требующих юридической проверки».
3) Генерация кода
- 💻 «Сгенерируй решение. Добавь тесты. Объясни сложность. Соблюдай стиль проекта».
- 🧪 «Если условия задачи неоднозначны — перечисли допущения перед кодом».
Для усиления результата полезно встроить внутреннюю перелинковку на сайте: например, «…об этом мы подробно писали в статье про RAG-подход для корпоративных баз знаний» и «…смотрите также материал про оценку качества LLM в продакшне».
🔒 Безопасность, качество и эксплуатация
При внедрении в компании критично закрыть три зоны:
- 🛡️ Контент-риски: политика ответов, запрещённые темы, маскирование PII, отказ от “догадок”.
- 📊 Качество: контрольные наборы запросов, A/B, метрики точности и полезности, регрессии.
- ⚡ Стоимость: лимиты контекста, кэширование, батчинг, выбор доменной конфигурации.
Риторический вопрос: вы точно измеряете качество на реальных кейсах пользователей, а не на “красивых демо”? На практике именно мониторинг и регрессионные наборы определяют успех внедрения.
Теперь, когда вы знаете основу архитектуры и логику внедрения, можно переходить к пилоту: начните с одного домена и 2–3 сценариев, соберите обратную связь, затем расширяйте контур.









Добавить комментарий