
AudioLDM 2 — это модель text-to-audio, которая генерирует реалистичные звуки по текстовому описанию: от саунд-эффектов и фоновых сцен до музыки и речи. Подход основан на латентной диффузии: вместо “рисования” аудио напрямую модель работает в компактном латентном пространстве и затем восстанавливает волну через декодер/вокодер. Такой дизайн помогает балансировать качество, скорость и управляемость результата.
На практике AudioLDM 2 удобен для продакшена, потому что его можно запускать в готовых пайплайнах (например, через Diffusers), а также пробовать онлайн в демо-интерфейсе — без локальной установки.
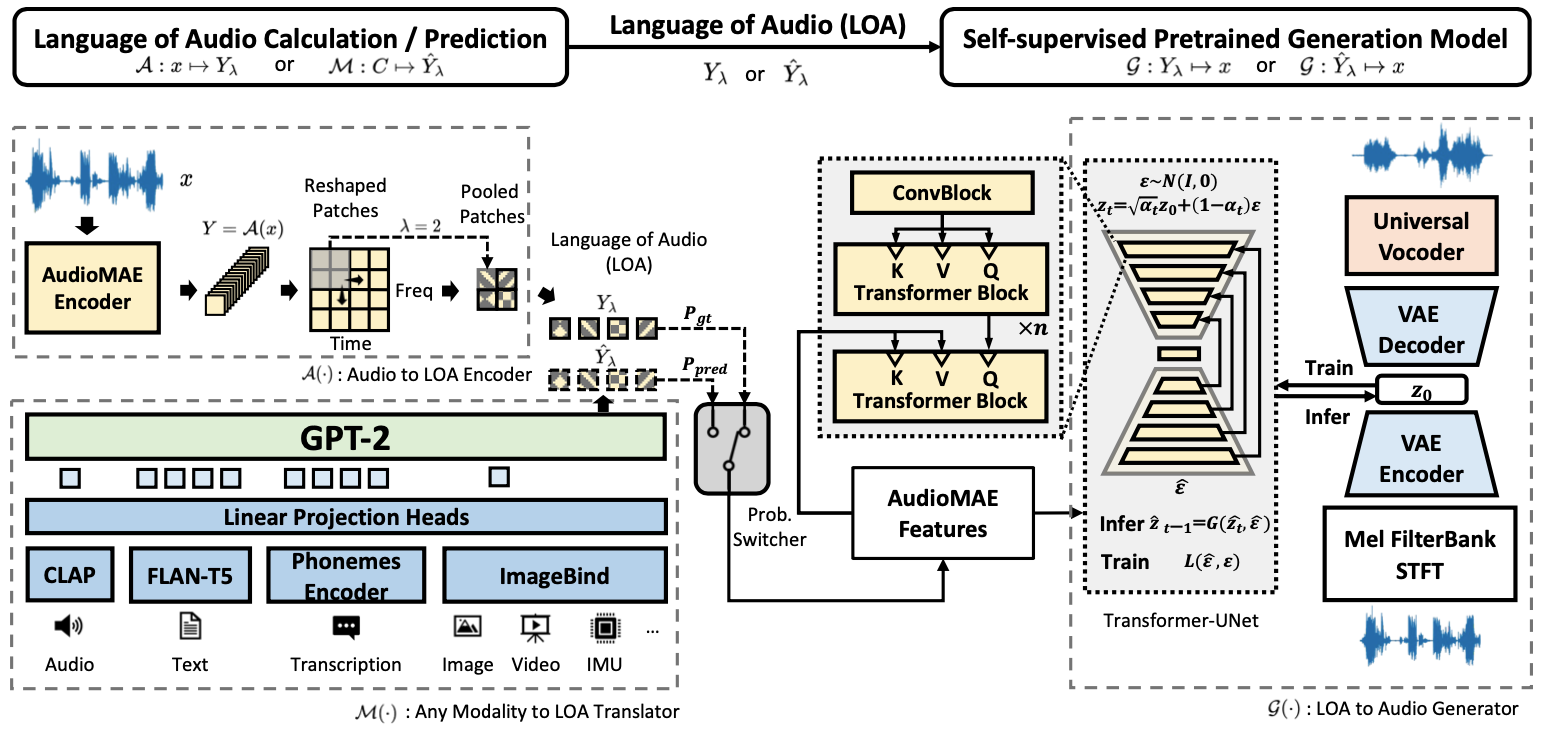
Схема: высокоуровневая архитектура AudioLDM 2 и ключевые блоки генерации звука.
🎧 Что умеет AudioLDM 2 и где её используют?
Главная идея AudioLDM 2 — “универсальный взгляд” на генерацию аудио. Вместо того чтобы держать отдельные модели для музыки, речи и SFX, подход стремится объединить их общей логикой обучения и представления. Это особенно полезно в задачах, где требуется быстро получать вариативные варианты звука под один и тот же сценарий.
- 🎬 Sound design: шаги, дверные звонки, дождь, толпа, механизмы, атмосферы для видео.
- 🎮 Игры: процедурные звуки объектов/событий (без ручной записи каждой вариации).
- 🎵 Музыка: жанровые петли, фоновые подложки, наброски аранжировок.
- 🎙️ Речь: генерация фраз с описанием голоса (в зависимости от чекпойнта/режима).
Практика: если нужен “живой” результат, всегда генерируйте 3–6 вариантов с разными seed и выбирайте лучший — качество у диффузионных моделей ощутимо зависит от случайности.
🧠 Как устроена модель: просто о сложном
AudioLDM 2 сочетает несколько компонентов: текстовые энкодеры для понимания промта, модуль, который связывает смысл и аудио-представление, а также диффузионную часть, которая “очищает” шум до целевого звука. Важный элемент концепции — Language of Audio (LOA): унифицированное представление, которое помогает модели быть “мультирежимной”.
Ключевые идеи:
- 🧩 Латентное пространство: работать быстрее и стабильнее, чем генерировать волну напрямую.
- 🔗 Сильные текстовые признаки: лучшее соответствие промту (что именно должно звучать).
- 🧪 Self-supervised pretraining: использование больших объемов аудио без разметки для укрепления генератора.
❓Почему “латентная диффузия” даёт качественный звук?
Потому что диффузия умеет аккуратно восстанавливать детали из шума по “условию” (тексту), а латентное пространство уменьшает размерность задачи. Это снижает вычислительную нагрузку и помогает модели удерживать структуру (например, характер тембра, ритм, “сцену” окружающего звучания).
Наблюдение экспертов: самые “сильные” промты — это те, где есть объект + действие + среда + стиль (например: “metallic impact, short tail, in a concrete hallway, cinematic”).
📌 Проблема → Решение → Результат (на реальном сценарии)
Проблема: в ролике нужно 15 вариантов звука “городской дождь + редкие машины”, а стоки звучат одинаково и быстро узнаются.
Решение: сгенерировать вариативный набор в AudioLDM 2, фиксируя стиль промта, но меняя seed и детали (“light rain”, “heavy rain”, “distant traffic”, “wet asphalt”).
Результат: вы получаете уникальные дорожки с близкой атмосферой, экономите время на поиске и избегаете “заезженного” стокового звучания.
⚙️ Как взаимодействовать с AudioLDM 2: 3 удобных способа
1) Самый быстрый старт: онлайн-демо (Hugging Face Spaces)
Если нужно просто протестировать идею — используйте веб-демо: вводите промт, выбираете настройки и слушаете результат. Это идеально для первичной оценки качества, подбора формулировок и поиска “рабочих” паттернов промта.
- Откройте демо AudioLDM 2 в браузере.
- Введите текстовый промт (лучше на английском, с конкретикой).
- Настройте длительность/шаги/seed (если доступно).
- Сгенерируйте 3–6 вариантов и выберите лучший.
- Сохраните аудио и зафиксируйте “удачный” шаблон промта для будущих задач.

Онлайн-демо удобно для подбора промтов и быстрых экспериментов со звуком.
2) Продакшен-подход: запуск через Diffusers (Python)
Если вы строите пайплайн (например, генерация звука под монтаж или ассеты для игры), удобнее использовать готовый пайплайн в Diffusers. Он интегрируется в Python-проекты и даёт контроль над шагами, длительностью, девайсом и параметрами генерации.
pip install --upgrade diffusers transformers accelerate scipy torchПример генерации (сохранение WAV):
from diffusers import AudioLDM2Pipeline
import torch, scipy
repo_id = "cvssp/audioldm2"
pipe = AudioLDM2Pipeline.from_pretrained(repo_id, torch_dtype=torch.float16).to("cuda")
prompt = "Cinematic rain in a city street, distant traffic, wet asphalt, realistic ambience"
result = pipe(prompt, num_inference_steps=200, audio_length_in_s=10.0)
audio = result.audios[0]
scipy.io.wavfile.write("audioldm2_rain.wav", rate=16000, data=audio)Практические настройки качества:
- ✅ Увеличивайте num_inference_steps для качества (в разумных пределах).
- ✅ Играйте с seed — иногда “идеальный” вариант появляется на 2–3 попытке.
- ✅ Делайте промт более конкретным: длительность события, место, материал, настроение.
- ✅ Если результат “грязный” — попробуйте укоротить длительность или уточнить источник звука (например, “distant” вместо “loud”).
Совет: для повторяемости в продакшене фиксируйте seed и храните “паспорта генерации” (промт, шаги, длина, версия модели).
3) Локально через CLI (командная строка)
CLI удобен, когда нужно быстро прогнать список промтов батчем или автоматизировать генерацию без кода приложения.
audioldm2 -t "A doorbell ringing in a quiet apartment, realistic, close perspective"
audioldm2 --seed 1234 -t "Ocean waves at night, soft wind, relaxing ambience"
audioldm2 -tl batch_prompts.txt🧾 Чек-лист промтов (сохраните себе)
- 📌 Объект: что звучит? (rain, footsteps, engine, crowd)
- 🎛️ Действие: что происходит? (ringing, crashing, humming, whispering)
- 🏙️ Среда: где? (hallway, forest, studio, city street)
- 🎬 Стиль: cinematic, lo-fi, documentary, realistic, vintage
- ⏱️ Детали: short tail / long tail, distant / close, soft / loud
Сохраните этот список себе — он ускоряет попадание “в нужный звук” в разы.
📊 Сравнение способов работы с AudioLDM 2
| Способ | Когда выбирать | Плюсы | Минусы |
|---|---|---|---|
| Онлайн-демо | Тест идеи, подбор промтов | Быстро, без установки | Меньше контроля, зависит от очереди |
| Diffusers (Python) | Продакшен, автоматизация | Контроль параметров, интеграция в пайплайн | Нужны зависимости и GPU для скорости |
| CLI | Батчи, быстро прогнать список | Просто, удобно для скриптов | Меньше гибкости, чем в коде |
🔗 Полезные сценарии: что ещё почитать на сайте
Если вы развиваете генеративный продакшен, логично дополнить этот материал практикой — например, об этом мы подробно писали в статье про оптимизацию скорости загрузки сайта (для страниц с аудио-превью) и в материале про настройку CDN для медиа.
✅ Мини-CTA
Теперь, когда вы знаете базовую механику, попробуйте один сценарий: сгенерируйте 5 вариантов одного звука с разными seed и сравните, как меняется “характер” аудио. Это лучший способ быстро “почувствовать” модель.

Фиксируйте seed и параметры — так генерации становятся повторяемыми и удобными для команды.









Добавить комментарий