
Cohere Command R и Command R+ — это семейство разговорных LLM, ориентированных на корпоративные сценарии:
длинный контекст, retrieval-augmented generation (RAG), вызов инструментов (tool use) и
цитирование источников прямо в ответах. Официальные спецификации, примеры и обновления удобнее всего
отслеживать в документации Cohere:
обзор моделей Cohere.

Иллюстрация: Command R+ как флагманская модель линейки Command для задач RAG и длинного контекста.
🧠 Что такое Command R и Command R+ и чем они отличаются?
Обе модели оптимизированы под диалоговое взаимодействие и работу с большим объёмом входных данных:
контекстное окно 128 000 токенов и типичный лимит до 4 000 токенов на вывод.
В актуальных идентификаторах (например, релизах 08-2024) они используются как отдельные model IDs
в Chat API v2.
Command R обычно выбирают, когда важны стоимость и скорость, а сценарий предполагает
более простую RAG-логку или одношаговый вызов инструментов.
Command R+ чаще берут под сложные RAG-пайплайны и многошаговый tool use (агентные сценарии),
где модель должна последовательно планировать действия и использовать результаты предыдущих шагов.
| Критерий | Command R | Command R+ |
|---|---|---|
| Лучше всего подходит для | Базовый/средний RAG, одношаговый tool use, экономичные внедрения | Сложный RAG, многошаговый tool use (агенты), более высокие требования к качеству |
| Контекст | Длинный контекст (128k) | Длинный контекст (128k) |
| Цитаты / “grounded” ответы | Поддерживаются (RAG citations) | Поддерживаются (RAG + fine-grained citations, в т.ч. для tool use) |
| Экономика | Обычно дешевле | Обычно дороже, но сильнее для “production-grade” пайплайнов |
Почему длинный контекст — это не просто “больше текста”?
Длинное окно контекста удобно для задач, где нужно удерживать историю диалога, политику компании,
выдержки из документации и результаты инструментов в одном запросе. Но возникает вопрос:
что важнее — уместить всё или грамотно структурировать? Практика показывает, что структурирование
(разделение на “системные правила”, “контекст”, “вопрос” и “ожидаемый формат ответа”) часто даёт
больше прироста качества, чем простое увеличение объёма текста.
Экспертный принцип: чем больше контекст, тем выше цена ошибки в структуре. Хороший промпт не “льёт” данные,
а задаёт роли, ограничения, формат и критерии проверки ответа.
🔎 Ключевые возможности: RAG, citations и tool use
1) RAG (Retrieval-Augmented Generation): ответы, привязанные к документам
В RAG-сценариях модель получает не только вопрос пользователя, но и подборку фрагментов документов.
В ответе она может вернуть цитаты, указывающие, какие фрагменты использовались. Это снижает риск
“галлюцинаций” и помогает проверять выводы.
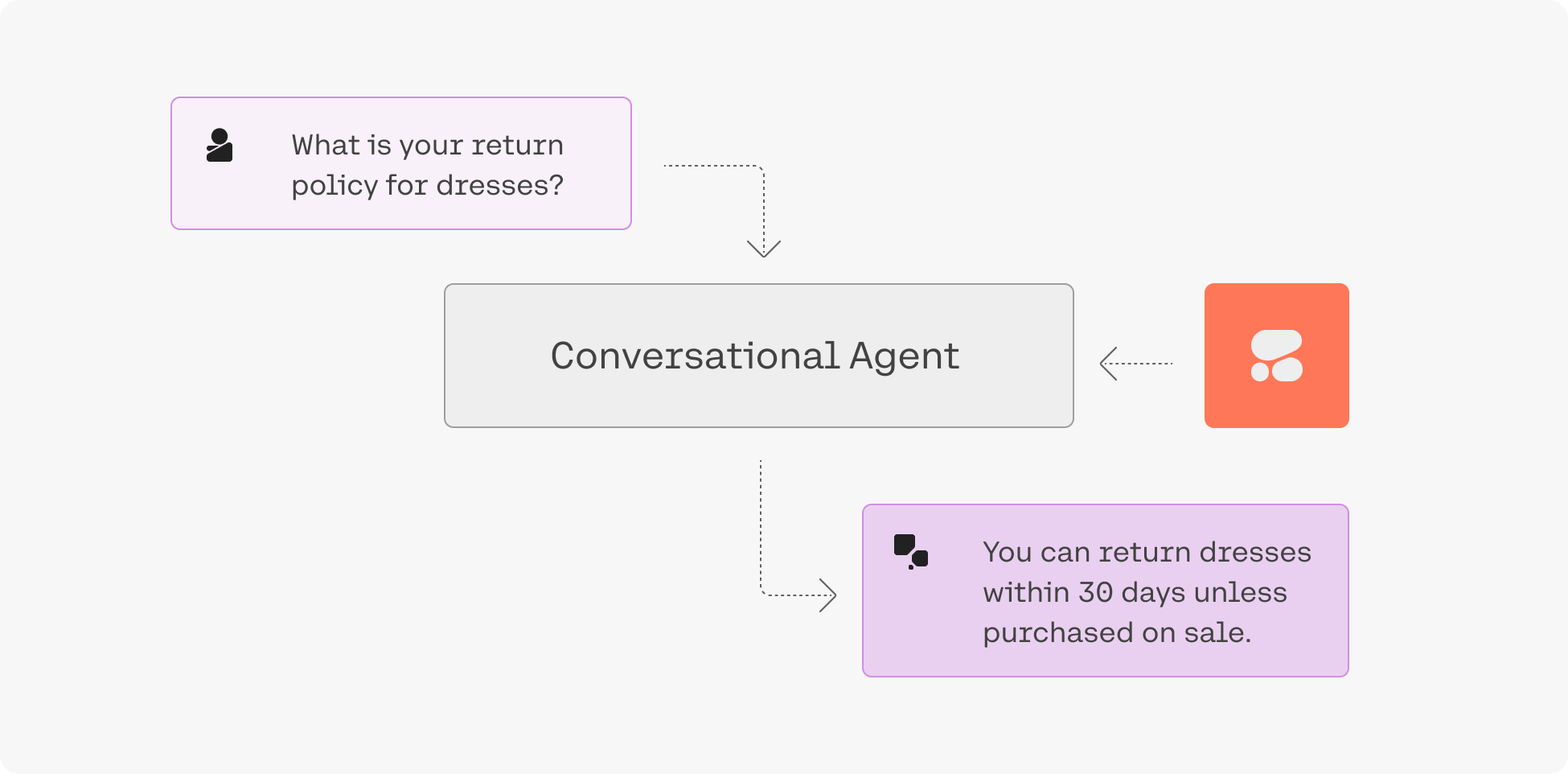
Схема: типовой разговорный агент, который может опираться на внешние источники данных (RAG).
2) Tool use: вызов функций, API и сервисов
Tool use позволяет подключать модель к вашим функциям: поиску, CRM, базе знаний, биллингу, календарю,
внутренним API. Модель определяет, нужно ли вызывать инструмент, формирует параметры и затем использует
результат для финального ответа.
- 🧩 Single-step tool use: модель вызывает один или несколько инструментов в рамках одного шага.
- 🧠 Multi-step tool use: модель может планировать цепочку действий, использовать результаты и повторять шаги.
- 🧾 Citations for tool use: в некоторых конфигурациях можно получать цитаты, связанные с действиями инструментов.
Проблема — Решение — Результат: если ответы “плывут” из-за нехватки фактов, подключение RAG и инструментов
(поиск/БД) переводит систему из режима “угадывания” в режим “проверяемых ссылок и данных”.
🧰 Пошаговая инструкция: как взаимодействовать с Command R / R+ через Cohere Chat API
Ниже — практический чек-лист. Сохраните этот список себе, чтобы быстро запускать интеграции и не терять
важные шаги при переносе в продакшн.
- Получите API-ключ Cohere в панели разработчика и настройте переменную окружения (например, COHERE_API_KEY).
- Выберите model ID под задачу: Command R для экономичного режима или Command R+ для сложного RAG/агентов.
- Сформируйте сообщения с ролями: system (правила), user (запрос), tool (результаты инструментов), assistant (ответ).
- Подключите RAG: передайте документы/фрагменты, которые должны “заземлять” ответ, и включите генерацию citations.
- Опишите инструменты (tool schemas): название, описание и поля аргументов, которые модель может заполнять.
- Включите потоковый режим (streaming), если важна скорость отображения ответа и UX в интерфейсе.
- Соберите telemetry: логируйте запросы, id диалога, tool calls, citations и метрики качества.
- Проверьте безопасность: используйте safety modes/политику модерации, если продукт работает с пользовательским контентом.
Пример запроса (шаблон) к Chat API v2
Важно: формат параметров зависит от выбранного SDK/языка. Ниже — универсальный шаблон, который удобно
адаптировать под Python/TypeScript/cURL.
POST https://api.cohere.com/v2/chat
Authorization: Bearer YOUR_API_KEY
Content-Type: application/json{
«model»: «command-r-plus-08-2024»,
«messages»: [
{«role»: «system», «content»: «Ты — корпоративный ассистент. Отвечай кратко, структурно, с проверяемыми ссылками.»},
{«role»: «user», «content»: «Составь план внедрения RAG для базы знаний отдела поддержки.»}
],
«documents»: [
{«title»: «FAQ», «snippet»: «Возвраты возможны в течение 30 дней при соблюдении условий…»},
{«title»: «SLA», «snippet»: «Ответ на тикет: приоритет P1 — 1 час, P2 — 4 часа…»}
],
«citation_options»: {«mode»: «accurate»},
«stream»: false
}
Как правильно “воспитывать” модель системным сообщением?
- ✅ 📌 Дайте роль и цель: “ассистент службы поддержки”, “аналитик”, “техписатель”.
- ✅ 🧾 Задайте формат ответа: пункты, таблица, критерии, ограничения по длине.
- ✅ 🔒 Добавьте политику: что нельзя раскрывать, как обращаться с персональными данными.
- ✅ 🧪 Опишите правило проверки: “если фактов нет в документах — честно скажи, чего не хватает”.
Теперь, когда вы понимаете базовую схему, стоит сделать следующий шаг: собрать 20–50 реальных запросов пользователей,
прогнать их через прототип с RAG и измерить качество по KPI (точность, время ответа, доля “не знаю”).
Именно так проще всего выбрать между Command R и Command R+ на ваших данных.
Комбинация Command + Embed + Rerank — частая основа для качественного RAG (поиск, ранжирование, генерация ответа).
✅ Практические советы для качества в продакшене
Как снизить “галлюцинации” без потери скорости?
Специалисты обычно используют связку: retrieval → rerank → grounded answer. Сначала извлекаются документы,
затем переранжируются (чтобы наверху были самые релевантные), после чего модель отвечает строго по контексту
и возвращает citations. А вы уже программно проверяете: есть ли ссылки, достаточно ли источников, не противоречат ли они друг другу.
Практика внедрений: лучше попросить модель сослаться на 2–4 фрагмента и “не додумывать”, чем получить длинный
красивый текст без опоры на документы.
📌 Мини-FAQ
Когда выбрать Command R+?
Когда система использует много источников, требует многошагового взаимодействия с инструментами или должна уверенно
обрабатывать длинные цепочки контекста с высокой стабильностью.
Когда достаточно Command R?
Когда сценарий проще (один шаг инструментов, базовый RAG) или критична стоимость при массовых запросах.
Если на сайте есть материалы про внедрение поиска и RAG, их полезно связать внутренними ссылками:
например, “об этом мы подробно писали в статье про оптимизацию базы знаний” и “в статье про построение RAG-пайплайна”.









Добавить комментарий