
TII Falcon 2 — серия открытых моделей от Technology Innovation Institute (TII), ориентированная на сильное качество при относительно компактном размере. Официальное описание линейки и ключевые особенности доступны на официальной странице Falcon 2 от TII — именно оттуда удобнее всего начинать знакомство и сверять актуальные релизы.
Почему вокруг Falcon 2 столько внимания? Потому что это «рабочая лошадка» для задач генерации текста, суммаризации, поиска ответов, а также (в версии VLM) — для понимания изображений и преобразования визуального контента в текст.

Иллюстрация инфраструктуры, на которой обычно запускают LLM: от локального инференса до серверных стендов.
🦅 Что такое Falcon 2 и из чего состоит линейка?
Под названием Falcon 2 обычно подразумевают два «ядра» серии: текстовую модель и мультимодальную VLM-версию. Обе построены как decoder-only (авторегрессионные) модели: они предсказывают следующий токен и поэтому хорошо подходят для генерации, диалогов и ассистентов.
Ключевые варианты, которые чаще всего используют на практике:
- 📌 Falcon2-11B — текстовая LLM на 11B параметров, удобная для чата, генерации, суммаризации, извлечения структуры.
- 🖼️ Falcon2-11B-VLM — vision-to-language модель, которая «читает» изображения и возвращает текст (описание, извлечение смыслов, ответы на вопросы по картинке).
Эксперты обычно рекомендуют начинать с базовой текстовой версии, а затем добавлять VLM в те пайплайны, где важны документы, скриншоты, фото товаров, схемы и визуальные проверки.
🔍 Чем Falcon 2 отличается от «типичной» LLM?
У Falcon 2 есть несколько практичных отличий, которые влияют на внедрение:
- ⚙️ Фокус на эффективности: модель рассчитана на запуск на сравнительно «легкой» инфраструктуре (вплоть до одного GPU в разумных режимах).
- 🌍 Мультиязычность: помимо английского, заявлена поддержка ряда европейских языков — удобно для международных проектов и смешанных корпусов.
- 🧩 Открытая экосистема: модель доступна через популярные инструменты развертывания и интеграции (включая Hugging Face).
Риторический вопрос: стоит ли выбирать «самую большую» модель, если задача — быстрый инференс, предсказуемая стоимость и стабильная интеграция? В реальных продуктах часто выигрывают именно сбалансированные решения вроде Falcon 2.
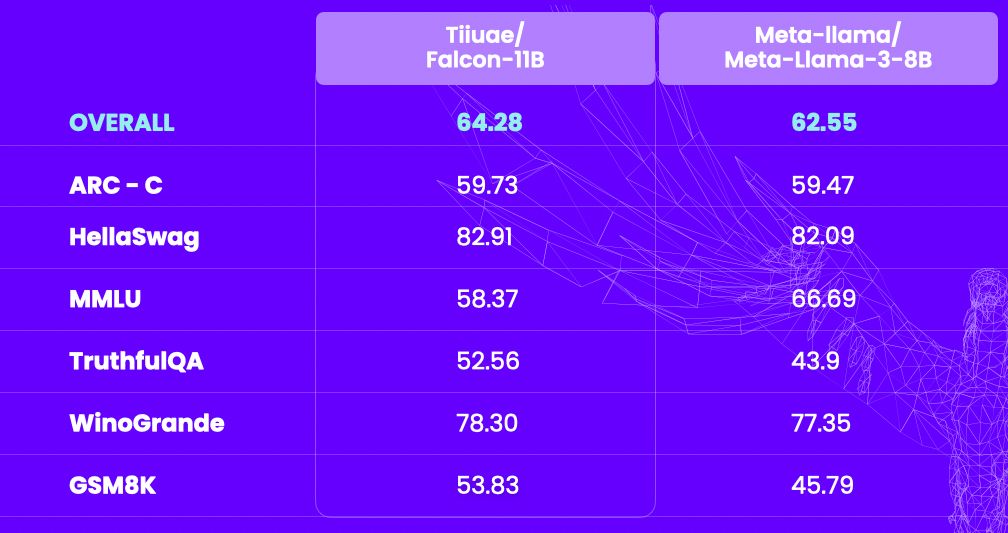
Визуальный пример сравнения результатов на популярных задачах оценивания качества (из материалов Falcon LLM).
🧠 Где Falcon 2 особенно полезен?
Falcon 2 хорошо «заходит» в сценарии, где нужен контролируемый продакшн: понятные требования к ресурсам, воспроизводимость, гибкость в настройке. Типовые кейсы:
- 📄 Суммаризация документов, писем, протоколов, звонков.
- 🧾 Структурирование: превращение текста в пункты, чек-листы, таблицы, планы.
- 💬 Саппорт-ассистенты (в связке с базой знаний и RAG).
- 🧷 Классификация и маршрутизация обращений.
- 🖼️ VLM-сценарии: описание изображений, ответы по скриншотам интерфейса, извлечение смысла из визуальных материалов.
Проблема — Решение — Результат
Проблема: компания получает сотни обращений в поддержку, где половина — скриншоты и «непонятные» описания ошибок.
Решение: подключить Falcon2-11B-VLM для извлечения текста/контекста со скриншотов и Falcon2-11B для нормализации запроса (категория, приоритет, краткое резюме, предложение шага решения).
Результат: специалисты быстрее понимают ситуацию, снижается время до первого ответа, а база знаний пополняется структурированными кейсами.
📊 Сравнение вариантов развертывания: локально, сервер, облако
Выбор способа запуска определяет скорость, стоимость и удобство обновлений. Ниже — ориентир, который помогает быстро принять решение:
| Вариант | Когда подходит | Плюсы | Минусы |
|---|---|---|---|
| Локально (PC/Workstation) | Прототипы, приватные данные, пилоты | Контроль данных, быстрый старт | Ограничение по ресурсам, нужно следить за окружением |
| Сервер/GPU-пул | Команда, несколько сервисов, стабильный трафик | Производительность, централизованное управление | DevOps-настройки, мониторинг, очереди |
| Управляемый API | Нужно «вчера», важны SLA и масштаб | Минимум инфраструктуры, быстрые релизы | Зависимость от провайдера, стоимость на больших объемах |
🛠️ Пошаговая инструкция: как взаимодействовать с TII Falcon 2
Ниже — практический путь от «первого запуска» до надежной интеграции. Сохраните этот список себе — он помогает не потеряться на старте.
- Определите сценарий: нужен только текст (Falcon2-11B) или также картинки/скриншоты (Falcon2-11B-VLM).
- Выберите среду: локально (для теста), сервер (для команды), API (для быстрого продакшна).
- Подготовьте окружение: актуальные версии Python, PyTorch и библиотек для работы с моделями.
- Возьмите модель из каталога: чаще всего используют репозитории на Hugging Face (по названию модели).
- Соберите промт-шаблоны: роль/контекст, требования к формату ответа, ограничения по стилю и длине.
- Настройте параметры генерации: длина, температура, top-p/top-k, стоп-слова — и зафиксируйте «дефолты».
- Добавьте защитные проверки: фильтры, правила, ограничение тем, логирование, трейсинг.
- Подключите RAG (если есть база знаний): индексация документов, поиск релевантных фрагментов, сбор контекста.
- Проведите тесты качества: набор эталонных запросов, сравнение версий, контроль регрессий.
- Запустите мониторинг: задержки, стоимость, частота ошибок, доля «плохих» ответов, дрейф данных.
✅ Чек-лист готовности к продакшну
- ✅ Есть эталонный набор запросов и критерии качества.
- ✅ Описаны форматы ответов (JSON/текст/таблица) и правила валидации.
- ✅ Настроены лимиты (длина контекста, таймауты, rate limit).
- ✅ Реализованы guardrails: запрещенные темы, политика приемлемого использования, логирование.
- ✅ Есть план на обновление модели и откат версии.
Практика показывает: качество в продакшне определяется не только моделью, но и дисциплиной вокруг промтов, тестов и мониторинга — это «скрытый множитель» эффективности.
🖼️ Как работать с Falcon2-11B-VLM: изображения, скриншоты, документы
VLM-версия особенно сильна в «офисных» сценариях: описание изображений, ответы по скриншотам, извлечение смысла из визуальных материалов. Важно заранее определить, что именно модель должна вернуть: краткое описание, структурированные поля, список проблем, рекомендации.
Удобный паттерн промта для VLM:
- 🧭 Контекст: «Ты — ассистент службы поддержки / юрист / аналитик».
- 🎯 Цель: «Опиши изображение и выдели 5 ключевых деталей».
- 📌 Формат: «Верни ответ списком, без лишних вступлений».

Пример интерфейса/демо, где VLM преобразует визуальный ввод в текстовый вывод.
⚖️ Лицензия и ответственное использование
Falcon 2 распространяется по лицензии семейства TII Falcon License 2.0 (на базе Apache 2.0 с дополнительными условиями). На практике это означает: модель можно использовать в коммерческих и исследовательских задачах, но важно соблюдать правила приемлемого использования, особенно в чувствительных доменах.
Если вы внедряете модель в продукт, специалисты обычно советуют:
- 🛡️ добавить правила безопасности и фильтрацию;
- 🧾 логировать запросы/ответы (с учетом приватности);
- 🧪 регулярно тестировать на смещение, галлюцинации и устойчивость к «плохим» запросам.
Компании, которые заранее закладывают политику безопасного применения, быстрее масштабируют ИИ-сервисы и реже сталкиваются с неприятными сюрпризами на росте трафика.
🚀 Практические советы по качеству ответов
Чтобы Falcon 2 выдавал более стабильные результаты, полезны простые, но системные приемы:
- 📎 Давайте примеры: один «идеальный» пример ответа часто улучшает формат сильнее, чем длинные инструкции.
- 🧱 Разделяйте задачи: сначала извлечь факты, затем — сформулировать выводы.
- 🧰 Уточняйте ограничения: «если данных не хватает — задай 2 уточняющих вопроса».
- 🔁 Фиксируйте шаблон: единый промт для команды снижает разброс качества.
Кстати, об этом мы подробно писали в статье про RAG-подход и в материале про оптимизацию скорости загрузки сайта — эти темы часто напрямую влияют на успешность AI-интеграций.
🎯 Мини-CTA
Теперь, когда вы понимаете устройство и сценарии TII Falcon 2, самое время перейти к практике: выберите один бизнес-кейс, подготовьте 30–50 эталонных запросов и «прогоните» модель в прототипе. Если результаты устраивают — масштабируйте на серверный инференс и подключайте мониторинг.

Открытые модели живут и улучшаются благодаря сильной исследовательской и инженерной культуре.









Добавить комментарий